


















































新闻资讯
聚焦企业新动态,刷新行业新认知

本月,DeepSeek V4 的正式发布在人工智能领域引发了一场地震。
在各大科技巨头纷纷建立技术壁垒的今天,DeepSeek V4 并没有走西方大厂的封闭路线,而是采用无商业限制的 MIT 协议完全开源。
在战略和技术层面,DeepSeek V4无情地戳破了过去几年主导AI行业的两个昂贵幻觉:只有依赖硅谷最新芯片才能实现前沿智能的“算力霸权”,以及盲目将海量数据塞入神经网络的“数据堆叠”迷信。

本次发布的DeepSeek V4 系列包含两款MoE(混合专家)模型:旗舰版 DeepSeek-V4-Pro(总参数1.6万亿,每次激活490亿)和极速版 DeepSeek-V4-Flash(总参数2840亿,每次激活130亿)。
其最核心的亮点包括:
1.标配百万级上下文窗口:
100万Token的上下文长度不再是昂贵的“高级增值服务”,而是V4系列所有官方接口的默认标配(等同于能一次性塞入中型代码库或十几本长篇小说)。
2.Agent能力专项优化:
V4 专门针对主流的智能体框架(如 Claude Code 等)进行了定向优化,让AI在执行复杂的代码任务和长文档生成时变得更加聪明和连贯。
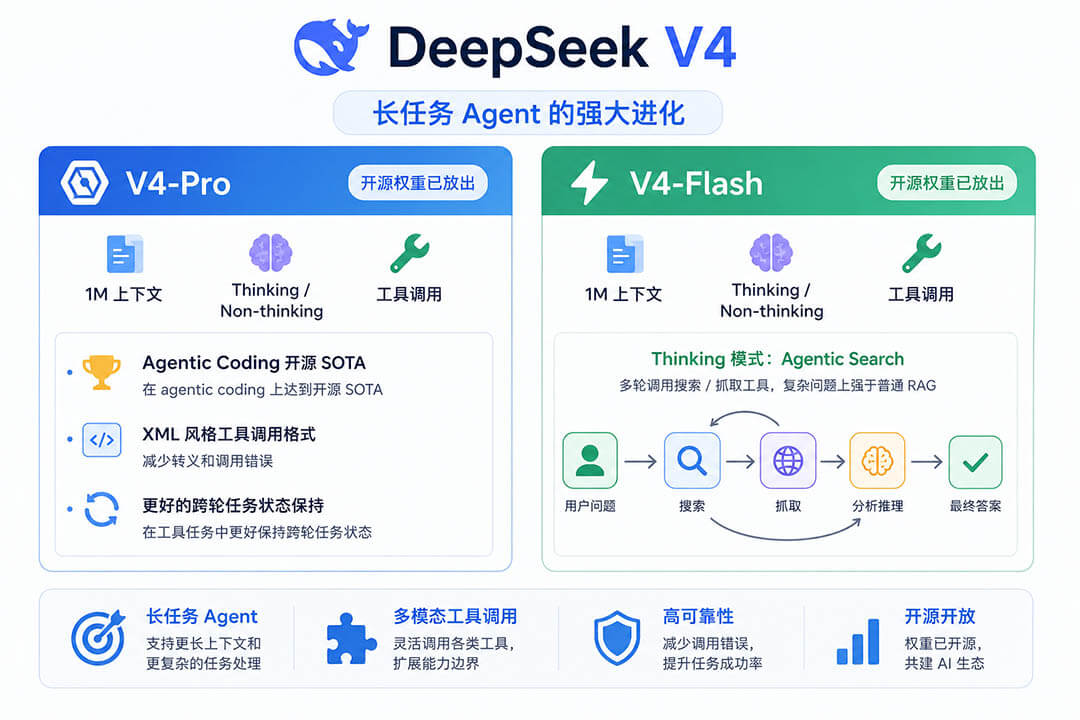
3.降维打击的定价策略:
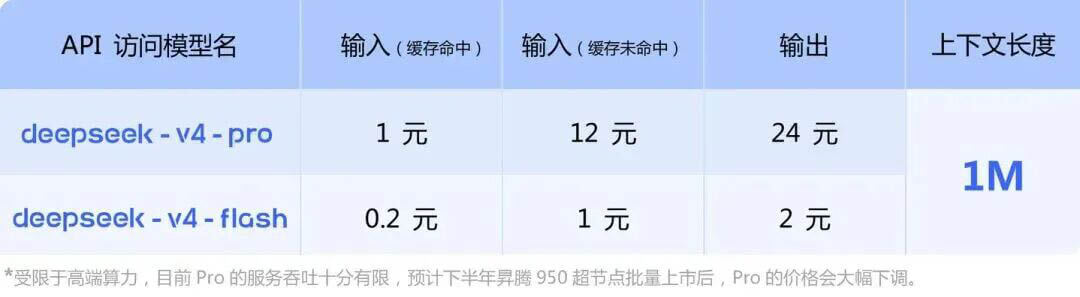
从定价逻辑可以看出,DeepSeek 正在通过“缓存命中”与“未命中”的显著价格差,鼓励开发者通过缓存优化来降低算力损耗,从而实现业务成本的精细化控制。
戳破幻觉一
2024算力霸权——“无英伟达则无前沿AI”
过去几年,整个 AI 行业的商业逻辑建立在一个脆弱的基础之上:大家普遍认为,想要让模型更聪明,就必须砸几百亿买更多、更贵的英伟达(NVIDIA)高端显卡。DeepSeek V4 彻底打破了这种“只有靠暴力算力才能出奇迹”的迷信。
首先是真正意义上的“硬件脱钩”。最令行业震动的是,DeepSeek 证明了不依赖西方最顶级的芯片,一样能练出最聪明的 AI。
V4 的推理与优化深度适配了华为昇腾 950PR 和寒武纪 MLU 等国产芯片。这不仅为中国 AI 巩固了优势,更向全球宣告:硅谷的算力垄断时代开始松动了。
其次,是用“算法巧思”降维打击“暴力算力”。DeepSeek 没有选择硬刚物理瓶颈,而是给模型换了两个极其聪明的“新脑子”:
不硬背,学“速读”(混合注意力机制 CSA+HCA): 以前的 AI 看百万字长文,采用的是“死记硬背”法,极度消耗显存(KV缓存),经常把机器撑爆。
V4 采用的混合注意力机制,好比让 AI 学会了“量子速读”——先粗看全局把握大意,再精准定位提取重点。这种巧思让 V4 在处理百万长文时,算力消耗下降了七成多,显存占用更是暴降了 90%。

给“传话游戏”加稳压器(流形约束超连接 mHC): 训练一个 1.6 万亿参数的超大模型,就像让几万个人同时玩“传话游戏”。在深层网络中,信号极其容易失真、放大,最后导致整个训练系统崩溃(学术上叫“梯度爆炸”)。V4 引入了一项新技术,相当于给整个传话系统安装了一个“稳压器”,只多花了不到 7% 的计算力,就把失真率死死压住,稳稳当当地把庞然大物训练了出来。
V4 的面世成功证明:在系统级架构创新面前,盲目扩大芯片带宽和算力规模的边际收益正在急剧递减。
戳破幻觉二
2024数据堆叠——“所有知识都在GPU里炼丹”
另一个被戳破的幻觉是数据处理的粗放模式。传统大模型将所有类型的数据(无论是一加一等于二的死知识,还是复杂的代码逻辑推演)混合在一起,全部塞进昂贵的GPU显存中进行神经网络计算。
这就像让顶尖数学家花大把时间去死记硬背一本《新华字典》,既浪费大脑,还容易记错。
DeepSeek V4 的底层设计则指出:知识检索与逻辑推理是两种完全不同的智能,必须分开处理。
为此,V4 引入了极具革命性的 Engram(印迹)记忆系统,打破了硬件的物理限制。这就好比给 AI 发了一本可以随时翻阅的“外接参考书”。模型把海量的“死知识”(如专有名词定义、公司说明书等)做成目录,卸载存放到极其便宜的普通电脑内存(CPU RAM)里。AI 需要用到这些知识时,花不到 3% 的时间就能瞬间“查阅”到精确答案。

这种将“查字典”和“动脑子”分开的设计,不仅极大省了钱,还让模型在浩如烟海的长文本里找特定信息的准确率飙升到了 97%。
这种底层技术的改变,直接重构了 AI 行业的“数据经济学”。 既然 AI 学会了“开卷考试”,企业就不能再把各种乱七八糟的数据一锅端喂给 AI 了,而是要分成两步走:
“喂”给外接参考书的死知识: 必须极其准确、高密度。因为这是去查字典,字典如果有错别字,AI 就会出错。
“喂”给 AI 大脑的推理数据: 必须包含清晰的逻辑链条和纠错过程,用来锻炼 AI “动脑子思考”的能力。
更重要的是,DeepSeek V4 完全开源,意味着这种具备 1.6 万亿参数的“顶级大脑”已经成了免费的公共基础设施(商品化)。
未来企业的核心竞争力,不再是“谁家自己做的大模型最聪明”,而是“谁的手里掌握着最优质的独家行业数据”。
结语:
DeepSeek V4 的问世,宣告了前沿AI从“算力主导”向“架构与数据双轮驱动”的范式转移。它不仅证明了在摆脱西方顶级芯片垄断后,我们依然能够触及甚至定义通用人工智能的边界,更通过极低的推理成本与本地化私有部署能力,把数据主权重新交还给了企业。
对于企业而言,现在的战略信号已经震耳欲聋:请立刻停止对大模型底层军备竞赛的盲目烧钱,去拥抱开源的基础设施。请将有限的预算和精力,转移到“高质量私有数据的资产化建设”和“特定领域的业务逻辑梳理”上。
在崭新的 AI 纪元里,决定企业护城河深度的,不再是你机房里囤了几十张昂贵的显卡,而是你手中掌握着多少无法被轻易复制的专属核心数据。

















 粤公网安备44010602012222
粤公网安备44010602012222

