


















































新闻资讯
聚焦企业新动态,刷新行业新认知

AI大模型应用机会将属于有长期且完备底层数据的企业。

2025年,当DeepSeek大模型以“现象级”姿态席卷全球时,中国企业家的AI焦虑指数达到峰值。
一大堆公司都在呼喊All in AI,有些企业买了DeepSeek 一体机,到处去找“应用场景”;这过程中反映出一些焦虑:大家都怕赶不上这趟车,仿佛不拥抱AI技术就沦为“数字难民”。
而为了初步缓解焦虑,很多公司都会对外宣称成功接入DeepSeek,背后的真实情况是技术负责人接入了API,或者私有化部署一下......

很多CEO 都在幻想AI 是那支能够把自己困扰已久的商业模式点石成金的魔术棒。但事实上,更多企业是被集体“割韭菜”。据沙丘智库调研,2024年国内大模型项目中,72%的企业因缺乏数据基建与行业认知,陷入“投入数百万、产出PPT”的困境。
数据基建
AI价值释放的“隐形天花板”
既然盲目跟风难以奏效,那AI大模型应用机会到底属于哪类企业呢?答案指向一个常被忽视的底层要素:数据基建。
当前企业AI转型热潮中,一个普遍的认知误区是认为大模型技术可以“即插即用”,实则AI落地存在显著的门槛。我们认为,AI大模型应用机会将属于有长期且完备底层数据的企业。
IDC研究报告指出,企业数据可利用率每提升10%,AI模型的有效性增加23%。但现实是:62%的中国企业存在数据孤岛,38%的关键业务数据仍以非结构化形式(图片、文档、视频)散落。这解释了为何OpenAI的技术白皮书强调:“高质量数据集的构建成本,往往超过算法研发投入。”

数据采集是第一步。以零售场景为例,数据采集需覆盖“人货场”数据(如消费者行为数据、商品流通数据、门店场景数据)构成AI模型的训练基础。例如,线上通过全程数据埋点,采集用户搜索、浏览、加购等行为轨迹,线下则通过IoT设备、门店收银终端、智能货架等设备采集多模态数据(图像、语音、交易记录),还原真实消费场景的复杂性,为模型提供细颗粒度输入。
数据治理则进一步将原始数据转化为资产。因为单纯的数据积累并不足够,企业需具备数据清洗、标注、结构化处理等能力,将零售场景中分散的订单数据、用户行为日志、商品属性等转化为高质量数据资产。
还有一点是数据迭代。建立动态反馈机制,基于前端消费者行为变化(如促销响应、偏好迁移),通过实时数据回流优化模型参数。
行业KnowHow
大模型时代的专属“护城河”
即便数据基建完备,AI落地仍可能遭遇另一个瓶颈:通用模型的局限性。
从这几个月的体验来看,我们觉得AI时不时地会“一本正经的胡说八道”。也许AI不是在故意撒谎,但肯定说明通用大模型依然不完善。尤其当涉及到一些具体领域,比如零售、金融、教育、医疗等,通用大模型的局限性就会显著。
MIT斯隆管理学院研究证实:注入行业专属知识的垂直模型,在特定场景下的ROI是通用模型的3-8倍。这意味着,AI的深度应用需要与行业Know-How深度融合,即具备丰富的行业专有语料数据,并将业务流程经验转化为模型训练的逻辑框架。
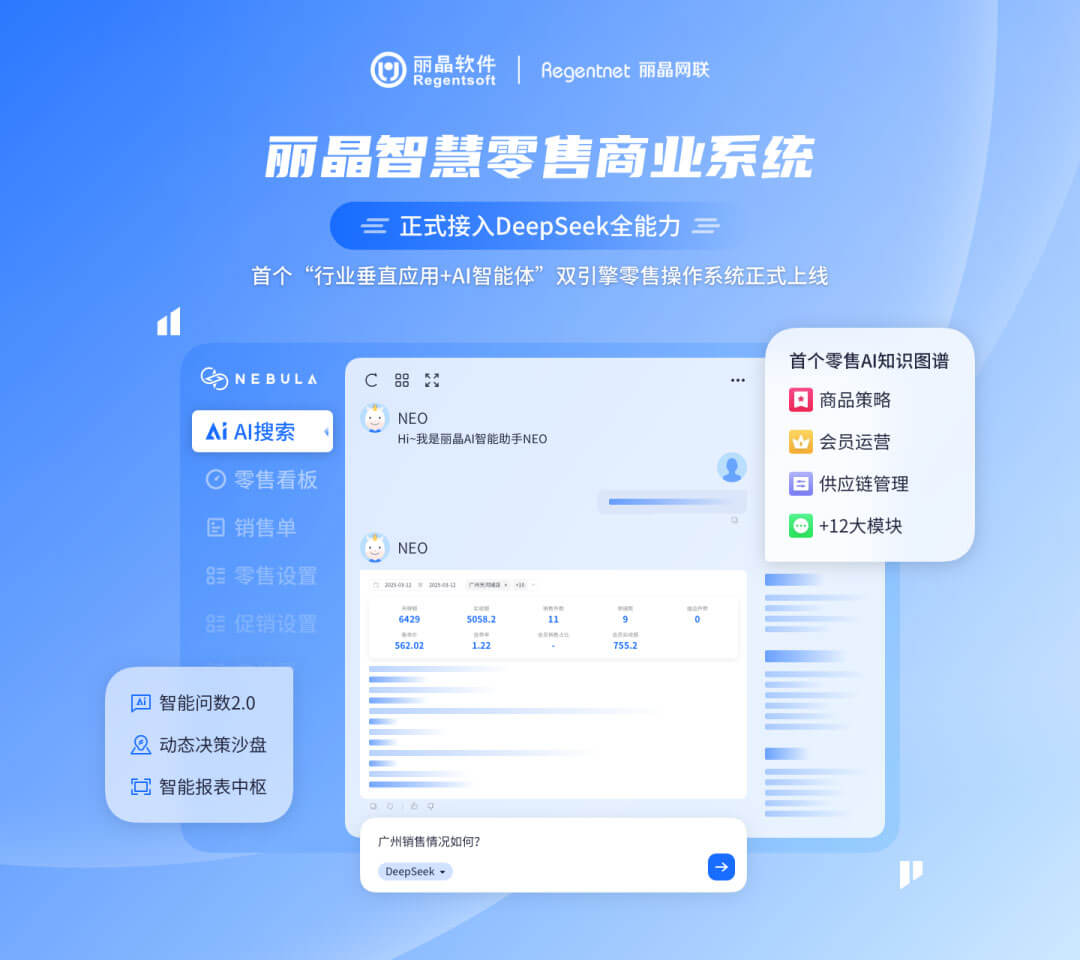
丽晶以20年零售行业KnowHow为根基,深度解构DeepSeek核心思维链,将多年积累的行业知识图谱、业务流数据与场景方案注入模型底层,构建行业首个支持AI智能体(AI Agent)规模化落地的零售智慧商业系统,从而加深加厚我们独有的行业Know-How护城河。
更多产品详情,请点击↓↓
写在最后
当AI炒作潮水退去,真正留存的将是那些把数据视为战略资产、将行业KnowHow深度融入商业基因的企业。唯有回归业务本质,在数据深挖与行业深耕中构建竞争壁垒,才能在这场认知革命中赢得未来。















 粤公网安备44010602012222
粤公网安备44010602012222

